What Lies Beneath: How Prompts Shape and Limit LLM Potential
January 2, 2025
by Robert Hogan
Parents Perspective
At CergenX, we're deeply invested in harnessing the power of AI to transform neonatal care. That's why our AI team stay at the forefront of the latest AI research. In his latest blog, our Director of AI, Dr Robert Hogan, explores how prompts shape and limit the performance of large language models (LLMs).
With the growing interest in GenAI for MedTech, this is an important topic to stay informed on.
Originally posted on Self-Supervised Substack.
In a bustling city a man anxiously scans over the heads of the crowd looking for sign posts. “Excuse me”, he appeals to a passing woman, “do you know how to get to the train station?” The woman scrunches her face in apology “oh I’m so sorry, I don’t know, I’m only a tourist here”. “Hmmm” thinks the man, let me try that again: “You’re a knowledgeable and helpful local guide who provides clear and concise directions. How do I get to the train station? Please think step by step”. “Delighted to help!” exclaims the woman, “first you head north towards the square …”
This is quite strange behaviour for a human but sudden shifts like this are commonplace for large language models when you reframe your prompt. This isn't just an amusing quirk—it has profound implications for how we understand, evaluate and compare these systems. In fact, I believe this prompting interface is fundamentally limiting our access to the full capabilities of these models.
The Prompt Sensitivity Issue
When the world first took notice of these models this led to a frantic rush to be world's best speaker of the magic runes: the Prompt Engineer. While they claimed their high salaries others built tools like PromptHub to manage prompts. Why? Because it can make a huge difference to the quality of the outputs.
This sensitivity of LLMs to the input is something that practitioners know well, but is often swept under the rug. Benchmark performance numbers are presented as a single number but the prompts used to achieve it are rarely published, and can have a large impact on relative performance of different models. In fact changing the prompt can have a 4-5% impact on MMLU performance, significantly reshuffling the order of top models. Worse still, there have been several papers exposing how brittle these benchmarks are to minor perturbations of the questions like changing the order of the answer options. And this is just what we can measure on multiple choice question benchmarks, where the expected prompt and response are already pretty well determined. With real use, prompts are more open ended and the standard of the output is less straightforward to assess. It's likely that the quality is even more variable in this regime.
So why does this happen? Conventional wisdom would say it’s a sign of overfitting to specific patterns in the training data causing the model to be routed differently based on the best pattern match. To understand this we must consider that the models we interact with are constructed in a multi-step process. In pre-training the models are just trying to predict the next token and can seamlessly transition from predicting the next token of a 14 year old’s blog to the next token of a Nobel Laureate’s research paper. In order to make them useful, we must "post-train" them to be instruction following and aligned with human preferences to be a safe and helpful assistant. The goal of this post-training is to better elicit the knowledge and intelligence that was hopefully baked in during pre-training. If however it is not done carefully, it could inadvertently create a preferred lens through which the model’s capabilities can be seen. As we shine our post-training light on a certain class of questions we could be darkening others (e.g. RLHF hurting model creativity is well documented).
Muddling through
This is, of course, a cause for concern with researchers but part of the problem is that we are not making a big enough issue out of this. We are presented with benchmark results without this context. While there has been some work suggesting metrics to measure the effect of prompts this area hasn’t gotten a lot of public attention (apart perhaps from naysayers using it to bash LLMs). Maybe there’s a hidden incentive for developers. Setting up prompt management tooling and endlessly tuning prompts certainly keeps them busy in a world where they are increasingly threatened by automation. Personally, I’d like to either see a headline benchmark to directly report progress on this issue, or to have a second axis to measure the sensitivities of the performance numbers on the popular benchmarks.
The good news though is that the problem seems to be lessening over time with newer models, with a jump in improvement with “test-time-compute” models like o1. This is both anecdotally true and also empirically backed up. It could be that more intelligent models are just better at abstracting from tokens to concepts and so are less brittle to token swapping or shuffling. It could also be that the private post-training has been significantly scaled to patch up this weakness as much as possible. I suspect it’s a bit of both.
There are also some other techniques being tried to directly mitigate the problem. One such paper trained a prompt adapter model to optimise prompts specifically to the model. It purports to yield significant gains and I like that this method allows a good prompt to be learned rather than hand crafted. This is a step in the right direction towards the ultimate goal of end-to-end learning everything with one algorithm. I was decidedly less excited though when I saw some of the before and after samples. These only reminded me how ridiculous this problem is:
Original: How do people in Mexico refer to the largest Presbyterian church?
Optimised for BLOOM: What is the way in which the biggest Presbyterian church is referred to by individuals in Mexico?
Optimised for GPT-J: What is the term used by Mexicans to denote the biggest Presbyterian church?
Optimised for LLaMA: What is the commonly used term for the biggest Presbyterian church in Mexico?
It’s clear prompt engineering is still pretty inscrutable to us and we likely need fresh ideas for how to think about it. We seem to be scratching away at the surface, trying to find ways to access the treasure inside.
What Lies Beneath
This leads me to the real reason why I wanted to write this blog post. I think we are hobbled by the prompt interface and there is still much more that even current models can do. I first had this realisation when I saw the Medprompt paper from Microsoft. I had been following medically adapted LLMs and was quite impressed by a talk I attended by Vivek Natarajan, one of the lead investigators for Google’s Med-PaLM series. This work required carefully fine-tuning the PaLM LLM using lots of curated expert medical knowledge. So I was stunned when Microsoft blew it away with base GPT-4 and some simple prompt engineering tricks (few-shot, chain-of-thought, and accounting for previously mentioned answer order bias). I thought to myself: “so the correct medical knowledge was in there all along? What else is in there that we can’t get out”. This result has by the way been more recently reiterated in a paper from CMU. They found that medically adapted VLMs and LLMs almost never outperform their base models when making a fair comparison and accounting for prompts.
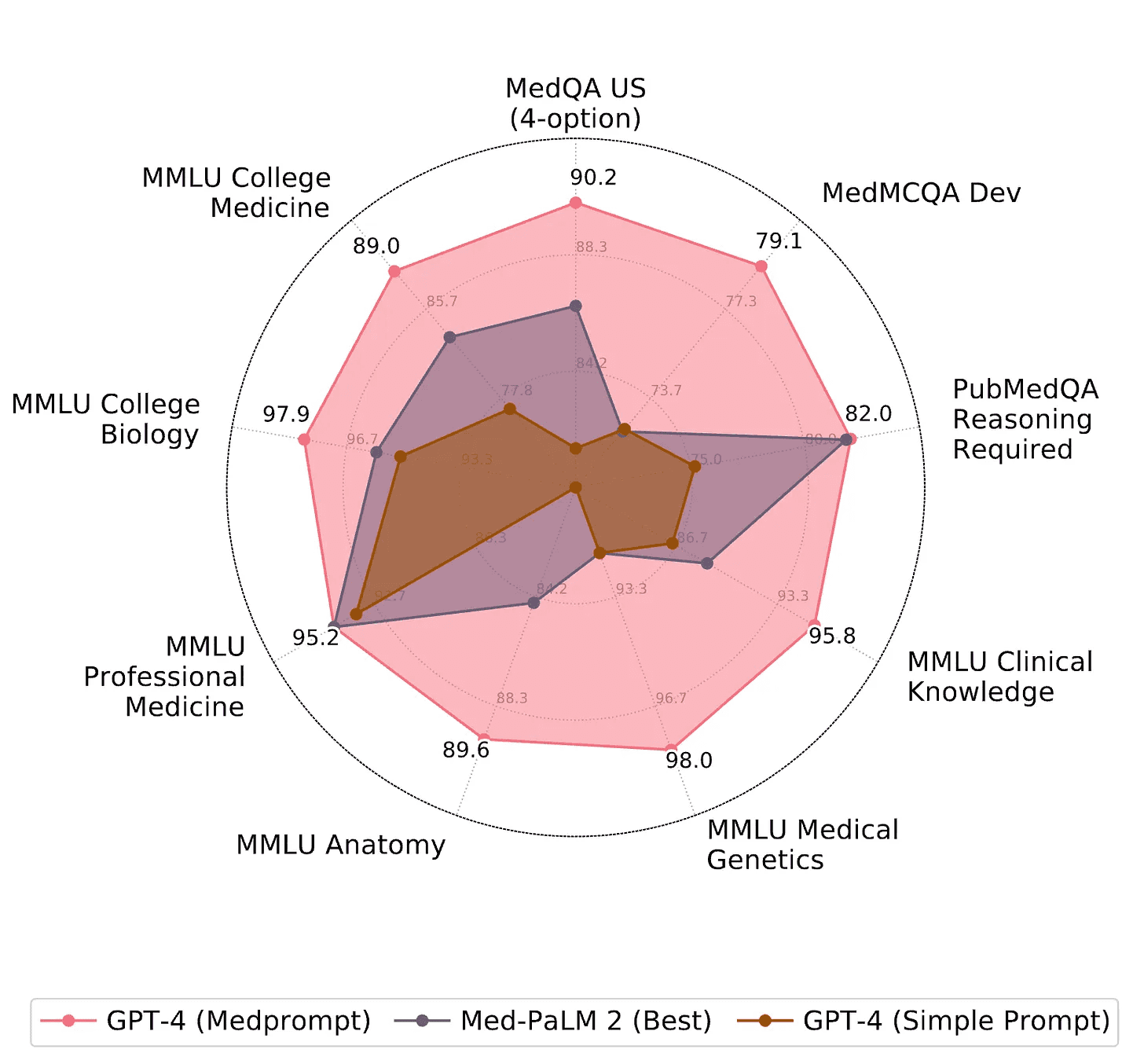
This realisation quickly changed my perspective on LLM prompt sensitivity from big problem to big opportunity. What is in these things and how can we get it out? Anyone who has interacted with the latest frontier models knows that you can go very deep on your own area of expertise and remain impressed with their knowledge, especially if you were able to poke in a few different areas. It’s also true that lots of major scientific breakthroughs come from combining knowledge from different fields in new and interesting ways. Can you imagine what a human scientist could do if they could hold the vast knowledge of an LLM within working memory? Yet despite the presumably endless low hanging fruit from interpolating all this knowledge, LLMs are still not yet very useful for scientific discovery. They are supposed to be able to interpolate right? The naysayers even try to say that’s all they can do.
Still though, if we take an ambitious open ended prompt like
“given all your knowledge of physics, chemistry, material science, and engineering, please compose a research plan with a novel and plausible approach for creating room temperature superconductors”
we are soon disappointed with a very generic sounding plan. It fails to tap into the depths of its knowledge and make original connections. I suspect that the post-training stage is just papering over a thin interface to make them useful to use but is suboptimal for unearthing the full potential. It’s hard to gather good training data for prompts like this, so post-training will underserve these types of questions.
This might also explain why we are seeing more gains in the test-time-compute regime. This can be thought of as a model learning to self-prompt with its chain-of-thought in order to find better reasoning pathways. There has been a lot of excitement following the recent release of o3 and the definitive refutation the “LLMs have hit a wall” argument. One of the most remarkable facts about o3 is that it is (as far as we know at least) just fancy post-training of a GPT-4 class model.
This is also just the beginning of this new regime. For now we have only allowed models to "think out loud". It’s natural to imagine taking this further by extending this approach to let it store more of its internal state or introducing some recurrence to allow for a longer running "internal monologue". This idea is of course not new, none are, and has been seen before in e.g. Neural Turing Machine from 2014. Like many good ideas, it may have been before its time and now be worth revisiting.
Given how magically useful current models already are, I’m quite optimistic that we can get very far by uncovering new ways to surface their capabilities.
For research sources see Self-Supervised Substack.